Node JS 동작원리
Node.js는 자바스크립트를 활용하여 고성능의 비동기 I/O를 지원하는 네트워크 애플리케이션(특히 서버 사이드) 개발에 사용되는 소프트웨어 플랫폼이다. (소프트웨어 플랫폼은 런타임과 동일한 개념이다. 반드시 소프트웨어가 포함되어야 한다. 플랫폼 자체는 하드웨어 뿐만 아니라 실제 세계에서 쓰이는 아주 넓은 표현이기때문이다.)
https://www.quora.com/Whats-the-difference-between-a-platform-and-a-runtime-environment
What's the difference between a platform and a runtime environment?
Answer (1 of 2): Hello there, These terms are used in computer technology a good deal. A platform is the hardware/software environment used to run a piece of software. So, for example, we have the PC Platform, which is the IBM Compatible Computer + OS (DOS
www.quora.com
위 사이트에서 David Kra님의 댓글이 플랫폼과 런타임의 차이를 명확히 말해주는 것 같다.
여기서 런타임이라는 말은 어떤 프로그램이 실행될 때의 환경이라고 한다.
https://searchsoftwarequality.techtarget.com/definition/runtime
What is runtime? - Definition from WhatIs.com
searchsoftwarequality.techtarget.com
Runtime is when a program is running (or being executable). That is, when you start a program running in a computer, it is runtime for that program.
위를 통해 런타임에 대해 정확히 이해할 수 있었다. 즉 어떤 프로그램이 컴퓨터에서 실행이 된다면, 컴퓨터가 런타임이 되는 것이다.
Node.js는 Single thread이지만, 완전한 싱글스레드를 기반으로 동작하지는 않는다 .
싱글스레드는 무엇일까? 싱글 스레드는 프로세스 내에서 하나의 스레드가 하나의 요청만을 수행한다. 한 번에 여러 요청을 수행할 수 없는 고, 싱글 스레드는 블로킹 모델이다. 반면 멀티스레드는 스레드 풀에서 실행의 요청만큼 스레드를 매칭 하여 작업을 수행하고, 논블로킹 모델로 분류할 수 있다.
Node.js는 싱글 스레드 논블로킹 모델이지만, 비동기 I/O 작업을 통해 요청들을 서로 블로킹하지 않는다.
이 말은 NodeJS는 싱글 스레드이지만 완전한 싱글스레드를 기반으로 동작하지는 않는다는 말과 같다.
이게 무슨 말일까?
일부 블로킹 작업들이 libuv의 스레드 풀에서 수행되기 때문이다.
여기서 말하는 libuv의 스레드 풀은 무엇이며? 그 작업은 어떻게 수행되는 것일
까?
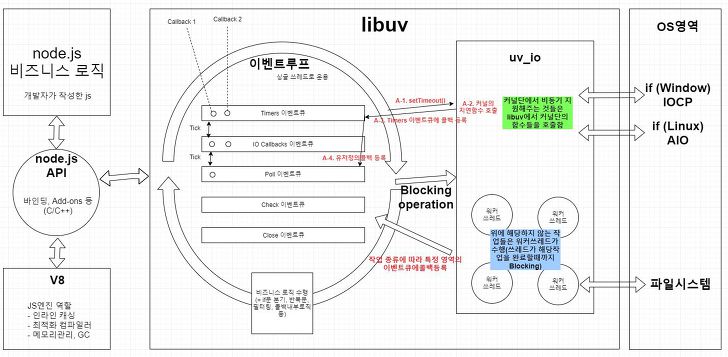
Node.js는 Google의 Chrome V8 자바스크립트 엔진을 기본으로 동작한다. 이를 기반으로 Single Thread 기반의 Event Loop (libuv)가 돌면서 요청을 처리한다.
Event Roop
이벤트루프는 메인스레드 겸 싱글스레드로서, 비즈니스 로직을 수행한다. 수행도중에 블로킹 I/O작업을 만나면 커널 비동기 또는 자신의 워커쓰레드풀에게 넘겨주는 역할까지 한다. 보통 웹어플리케이션에서 쓰니, 웹으로 예를 들자면 request 가 들어오면 라우터태우기, if문분기, 반복문돌며 필터링, 콜백내부로직 등은 이벤트루프가 수행하지만 DB에서 데이터를 읽어오거나(DB드라이버 개발자가 물론 비동기타게 짜야..) 외부 API콜을 하는 것은 커널 비동기 또는 자신의 워커쓰레드가 수행한다. 동시에 많은 요청이 들어온다해도 1개의 이벤트루프에서 처리한다. 위의 이벤트 루프는 libuv 라이브러리에서 구현된다.
Node.js에서 작성되는 거의 모든 코드들은 콜백 함수로 이루어져 있는데, 이 콜백 함수들은 libuv 내에 위치한 이벤트 루프에서 관리 혹은 처리된다. 이벤트 루프는 여러 개의 페이즈 들을 갖고 있으며 해당 페이즈들은 각자만에 큐를 가지고 있다. 이벤트 루프는 라운드 로빈 방식으로 노드 프로세스가 종료될 때까지 여러 페이지들을 계속 순회한다. 페이즈들은 각각의 큐들을 관리하고 각각의 큐는 FIFO 순서로 콜백 함수들을 처리하게 된다.
이벤트 루프는 큐의 자료구조를 포함하고 있지만, 전체적으로는 스택의 자료구조를 갖고있다.
여기서 라운드 로빈 방식이란 라운드 로빈 스케줄링(Round Robin Scheduling, RR)을 가리킨다.
라운드 로빙 스케줄링은 시분할 시스템을 위해 설계된 선점형 스케줄링의 하나로서, 프로세스들 사이에 우선순위를 두지 않고, 순서대로 시간단위(Time Quantum)로 CPU를 할당하는 방식의 CPU 스케줄링 알고리즘이다. 보통 시간 단위는 10 ms ~ 100 ms 정도이다. 시간 단위동안 수행한 프로세스는 준비 큐의 끝으로 밀려나게 된다. 문맥 전환의 오버헤드가 큰 반면, 응답시간이 짧아지는 장점이 있어 실시간 시스템에 유리하다.
이벤트 루프의 내부 동작 과정
이벤트 루프는 6 phase 들로 구성되어있다. 각 phase 들은 FIFO 큐를 가지고 있으며, 이 큐에는 특정 이벤트의 콜백들을 넣고, CPU가 할당(=이벤트루프가 해당 phase를 호출할때)될 때 실행한다. 아래는 phase들이다.
- timers
- setTimeout()과 setInterval() 과 같은 타이머 콜백들이 처리된다.
- 코드를 보면 이벤트루프가 uv__run_timers() 호출할때 타이머 콜백들을 받고, 실제 유저로직은 timer_cb인데, 이걸 poll 큐에 등록해버린다.
- 따라서 타이머 콜백 내부로직들은 poll큐에 먼저 등록된 콜백들이 처리되고 나중에 처리될 수도 있으므로, 파라미터로 지정한 시간에 딱 실행됨을 보장하지 못한다. 즉, 파라미터는 일정 시간 이후에 실행된다는 기준 시간같은 셈이다.
- ex. setTimeout(?, 100) 은 100ms 이후 언제 실행될지 모름. (poll 큐가 비어있다면 100ms 후 딱 실행되겠지만..)
- I/O callbacks: 클로즈 콜백, 타이머로 스케줄링된 콜백, setImmediate()를 제외한 거의 모든 콜백들을 집행
- http, apiCall, DB read 등..
- 이것 역시 작업완료는 이벤트루프가 I/O callbacks 영역을 호출(uv__run_pending())할 때 체크할 수 있지만, 이후에 콜백이 poll 큐에 등록되므로, 이벤트루프가 poll 영역을 처리할때 콜백 내부로직이 실행된다.
- idle, prepare
내부용으로만 사용 (모든 큐가 비어있으면 idle이 되면서 tick frequency가 떨어짐=할일도없으니 이벤트루프가 천천히 돈다고 한다.) - poll :poll 큐에 있는 이벤트 콜백들을 처리한다. 이때 poll에 쌓인 콜백 함수들을 실행하게 되는데 더 이상 실행할 콜백 함수가 없을때에는 규칙에 따라 다음 단계로 넘거가거나 대기하게 된다. 일단 check 단계를 검사하여 setImemediate 가 있는지 확인하고 setImemediate 가 있으면 check 단계로 넘어가게 된다. 만약 setImemediate 가 없다면 timer 단계에 실행할 timer 함수가 있는지 확인하게 된다. timer 단계로 넘어갈 수있을때까지 대기하고 도중에 poll 큐에 콜백함수가 들어온다면 즉시 실행한다.
- check :setImmediate() 콜백은 여기서 호출되고 집행된다.
- close callbacks : .on('close', ...) 같은 것들이 여기서 처리된다.
libuv 라이브러리
Node.js는 기본적으로 libuv 위에서 동작한다.
Node.js에서 논블로킹 I/O 모델이란 Input과 Output이 관련된 작업 예를 들면,데이터베이스 CRUD, 파일 시스템같은 블로킹 작업들은 백그라운드에서 수행하고, 이 수행한 작업들을 비동기 콜백 함수로 이벤트 루프에 전달하는 것을 의미한다.

I/O 작업들은 OS 커널 혹은 libuv 내의 스레드 풀에서 담당하게 된다. libuv는 OS 커널에서 어떤 비동기 작업들을 지원해주는지 알고 있기 때문에 작업 종류에 따라서 커널 혹은 스레드 풀로 분기(기본값은 4개의 스레드)한다. libuv의 스레드풀은 커널이 지원안하는 작업들을 수행하게 된다. 또한 libuv 의 스레드 풀은 멀티 스레드로 이루어져 있다. 예를 들어 파일 시스템은 libuv에서 처리되게 되고 스레드 풀도 마찬가지로 Node.js의 I/O 모델에 따라 작업을 마친 후 이벤트 루프에 콜백 함수를 전달하게 된다.
실제 코드를 통한 예시
setTimeout(() => {
console.log('timeout');
}, 0);
setImmediate(() => {
console.log('immediate');
});위 코드를 실행하게 되면, Node.js는 어떤식으로 작동하게 될까?
setTimeout()은 이벤트 루프 phase에서 time 쪽으로 들어가고, setImmediate는 check 쪽으로 들어가게 된다. 라운드 로빙 방식에 따른 위치가 어디에 있느냐에 따라 달라지는데 만일 timer 단계라면 setTimeout()이, check단계라면 setImmediate가 실행이 될 것이다.
기존의 유저가 직접 다룰 수 있는 스레드가 단일이었기때문에 Node.js가 싱글 스레드로 정의내려진 것
Node.js를 프론트엔드 개발자들이 공부를 해야하는 이유는 리액트 자체가 node.js 기반으로 만들어진 것이어서
node.js가 런타임인데 그 부분에 대한 이해가 없는 상태에서 리액트를 쓰는 것이 과연... 제대로 된 이해고 제대로 된 코드를 생각해낼 수 있을까? 당연 없다.
jquery의 런타임은?
뭔가를 배울 때, 내가 이걸 왜 배우지? 에 대해서 정확하게 알아본 다음에 하자.
그리고 어떤 걸 배울 때, 공식문서 무조건 읽어보자. 공식문서들 엄청 상세하게 적어 놓는다.
공식문서부터 읽는 습관을 들이자. 이제는 네이버 검색하는 대학생에서 탈출해야 한다... ㅠ
공식문서 보고도 이해가 안되는 부분이 있다면, 그때 다른 곳에서 찾아보는 것이 좋다.
Node.js가 등장한 이후로 자바스크립트가 어떻게 변하게 되었는가?
Node.js가 나옴으로써 자바 스크립트의 런타임이 브라우저에서만 되던 것이 더욱 넓게 확장되었다. (애플리케이션, 로컬데스크탑등)
서버에서도 쓰이고, 어플리케이션에서도 쓰이고, 눈에 보이는 모든 부분을 자바스크립트로(일렉트론 라이브러리)
자바스크립트 하나만으로 프론트엔드와 백엔드를 전부 다를 수 있게 해주었다. (런타임이기 때문에)
브라우저 이외의 실행환경을 제공해줬기 때문에.
C,C#은 닷넷프레임 워크 기반 런타임이 필요하지 않다. 컴파일만해서 실행하면 되니까. --> 찾아보기
C,C#은 운영체제가 런타임이나 다름 없다?
'개발 R.I.P.' 카테고리의 다른 글
| 7.06 Dev.Feedback (프로그래밍 패러다임) (0) | 2021.07.06 |
|---|---|
| 7.05 Dev.Feedback ( React #7 컴포넌트 디자인) (0) | 2021.07.05 |
| 7.03 Dev.Feedback (Side Effect) (0) | 2021.07.03 |
| 7.01 Dev.Feedback (미들웨어) (0) | 2021.07.01 |
| 6.30 Dev.Feedback (HTTP/ Network) (0) | 2021.06.30 |